Amazon S3 is a storage which can be accessed through simple web services interface. This web service interface can be used to store and retrieve data. The data can be retrieved from anywhere on the web at any time and any moment. Using this interface we can write applications which can access highly scalable, reliable, fast and cheap data storage. Amazon uses same storage for running their global web sites. The main benefit of it is the scalability; we do not have to care for limit of the storage. We do not have to think about the number of objects we want to store, size of an objects, or type of the object. We just get simple APIs and that’s all, and all the complexities of scalability, reliability, durability, performance are handled by Amazon S3. Amazon S3 takes away the headache of handling the issues generally associated with big storage systems. Amazon S3 is a based on distributed systems technologies. It uses replication across multiple devices and facilities. It is said that S3 stores 6 copies of data for HA and redundancy. It is designed to provide 99.999999999% durability and 99.99% availability of objects over a given year. Amazon S3 also provides Versioning, we can use Versioning to preserve, retrieve, and restore every version of every object stored in S3. It helps to recover data from both unintended user actions and application failures.
Amazon is now come up with Reduced Redundancy Storage (RRS) within Amazon S3 with lower cost than normal S3 for storing non-critical, reproducible data at lower levels of redundancy than Amazon S3’s standard storage. It stores objects on multiple devices across multiple facilities, providing 400 times the durability of a typical disk drive, but does not replicate objects as many times as standard Amazon S3 storage does. It is designed to provide 99.99% durability and 99.99% availability of objects over a given year.
Amazon standard S3 is designed to sustain the concurrent loss of data in two facilities, while the Reduced Redundancy Storage option is designed to sustain the loss of data in a single facility.
Amazon S3 stores data as objects within buckets. An object is comprised of a file and optionally any metadata that describes that file. S3 accounts can have a maximum of 100 buckets, each with unlimited storage and an unlimited number of objects. Each object can have 1 byte to 5 GB of data.
We can use Amazon S3 in many ways, some examples are:
1st we have to register and create our account. After registration process is completed, there is a process to active the account. Here I have to provide a telephone number and in that number will get a call from Amazon for verification.

I will be provided with a PIN and I have to input that PIN displayed in the screen to the telephone call.

After that my account verification is completed.
Now I will login to my AWS Management Console

Once log in, go to the Amazon S3 tab.
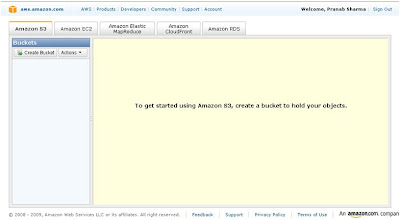
Right now I do not have any buckets created. So I am going to create a bucket to store the diagrams created by the IT Infrastructure team. Click on Create Bucket button or go to Actions -> Create Bucket

Now we have to enter the bucket name and region where this bucket will be created.

The bucket name you choose must be unique across all existing bucket names in Amazon S3. One commonly followed way is to prefix bucket names with the company’s name, so that it remains unique. Bucket names must comply with the following requirements:
We have to select the bucket region from Region drop down list. We must plan properly to choose a region to optimize latency, minimize costs, or address regulatory requirements. An objects stored in a region can never leave that region unless it is explicitly transferred to another region. The default region is US Standard, in our case I will select Singapore region to reduce the latency.
We can enable logging for the bucket to get detailed access logs delivered to the bucket using the Set Up Logging button

Click on Create button to create the Bucket. Now our bucket mkcl-itinfra-diagram is created.

We can specify permission and logging for this bucket from its properties. Right click on bucket name and click on Properties.

As shown in the screenshot we can Add more permission and remove any existing permission for this bucket

To upload files into the bucket click on the Upload button

Select the files to upload using the Add more files button

Click on Start Upload to upload the files.

Now my files are uploaded, now we will find the link for the image. Right click on the object and click on Properties.

The link for the image can be seen in the Details tab.

Now copy the link and we will try to open it in a browser.

Oopssssss….. HTTP 403 error, that means we do not have permission to view this image. So we have to change the access permission for this file so that we can access it publicly. Go to the Permissions tab in the Properties of the file and click on Add more permission, Select Everyone from Grantee list and tick on the Open/Download check box and click Save.

Now try to open the file in browser again……….. and this time I can see the image.

Using the Amazon APIs we can do all the S3 tasks programmatically.
Also there is a very good Firefox plugin called S3Fox Organizer to manage the S3 accounts. It can be downloaded from http://www.s3fox.net/ . Download and install it. After installation it will come under the Tools menu of Firefox

Now run S3 Organizer. At the first run it will show the alert message to add account information and key.

Click on Manage Accounts button of S3Fox. It will ask for the Account Name and the keys. The keys are created at the time of setup of the AWS access account.

This information is available in the Security Credentials link in the Account section of http://aws.amazon.com

Copy and paste the Access Key and Secret Key from Access Credentials in Security Credentials page into the S3 Account Manager window and click on Add button to add the account information. Close this window and go to S3fox Organizer. It has a very simple graphical FTP client like interface. Left hand side I can browse my local storage and in the right side I can see my S3 account root location with my Buckets. We can see the mkcl-itinfra-diagram bucket that we have created using AWS Management Console. Now I will create another Bucket called mkcl-cloud-pricing.

Click on Create Bucket/Directory button

S3Fox do not provide option to select the Region for the bucket, by default it creates the bucket in US Standard region, but it has a option to place the bucket in Europe. It do not have the Singapore option in Region list (as Singapore is a new region, so I think in the new version of S3Fox all the new regions will come). Also it does not provide the option to set Logging for the bucket.

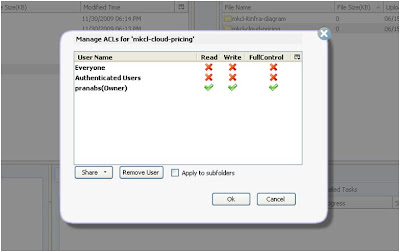
After creating the Bucket we can set the access control to that bucket by right clicking the bucket and clicking Edit ALC

Change the ALC as per requirement.
Also it has a cool feature to sync a local folder with a Amazon S3 folder. Click on the Synchronize Folders->Add/Remove Folders

Enter the folders to share and save it with a name.
After adding the folders we can sync the folders. Click on Synchronize Folders and on the name of the account that we want to sync (in our case the account Cloud_Pricing we created in the previous step).

It will give us alert message whether we want to upload all the files or only the files that were changed since last upload. If we click OK it will upload only the changed/new files and if we click Cancel, it will upload all the files.

I will click OK and the uploading will start.

Amazon S3 is a very good storage over internet. It can reduce online backup cost; also it is very reliable, flexible and fast. We can write our own applications or we can use the available tools to access S3.
Amazon is now come up with Reduced Redundancy Storage (RRS) within Amazon S3 with lower cost than normal S3 for storing non-critical, reproducible data at lower levels of redundancy than Amazon S3’s standard storage. It stores objects on multiple devices across multiple facilities, providing 400 times the durability of a typical disk drive, but does not replicate objects as many times as standard Amazon S3 storage does. It is designed to provide 99.99% durability and 99.99% availability of objects over a given year.
Amazon standard S3 is designed to sustain the concurrent loss of data in two facilities, while the Reduced Redundancy Storage option is designed to sustain the loss of data in a single facility.
Amazon S3 stores data as objects within buckets. An object is comprised of a file and optionally any metadata that describes that file. S3 accounts can have a maximum of 100 buckets, each with unlimited storage and an unlimited number of objects. Each object can have 1 byte to 5 GB of data.
We can use Amazon S3 in many ways, some examples are:
- Backup and Storage
- Application Hosting
- Media Hosting to hosts video, photo, or music uploads and downloads
- Software Delivery
1st we have to register and create our account. After registration process is completed, there is a process to active the account. Here I have to provide a telephone number and in that number will get a call from Amazon for verification.

I will be provided with a PIN and I have to input that PIN displayed in the screen to the telephone call.

After that my account verification is completed.
Now I will login to my AWS Management Console

Once log in, go to the Amazon S3 tab.

Right now I do not have any buckets created. So I am going to create a bucket to store the diagrams created by the IT Infrastructure team. Click on Create Bucket button or go to Actions -> Create Bucket

Now we have to enter the bucket name and region where this bucket will be created.

The bucket name you choose must be unique across all existing bucket names in Amazon S3. One commonly followed way is to prefix bucket names with the company’s name, so that it remains unique. Bucket names must comply with the following requirements:
- Can contain lowercase letters, numbers, periods (.), underscores (_), and dashes (-)
- Must start with a number or letter
- Must be between 3 and 255 characters long
- Must not be formatted as an IP address
- Bucket names should not contain underscores (_)
- Bucket names should be between 3 and 63 characters long
- Bucket names should not end with a dash
- Bucket names cannot contain two, adjacent periods
- Bucket names cannot contain dashes next to periods
We have to select the bucket region from Region drop down list. We must plan properly to choose a region to optimize latency, minimize costs, or address regulatory requirements. An objects stored in a region can never leave that region unless it is explicitly transferred to another region. The default region is US Standard, in our case I will select Singapore region to reduce the latency.
We can enable logging for the bucket to get detailed access logs delivered to the bucket using the Set Up Logging button

Click on Create button to create the Bucket. Now our bucket mkcl-itinfra-diagram is created.

We can specify permission and logging for this bucket from its properties. Right click on bucket name and click on Properties.

As shown in the screenshot we can Add more permission and remove any existing permission for this bucket

To upload files into the bucket click on the Upload button

Select the files to upload using the Add more files button

Click on Start Upload to upload the files.

Now my files are uploaded, now we will find the link for the image. Right click on the object and click on Properties.

The link for the image can be seen in the Details tab.

Now copy the link and we will try to open it in a browser.

Oopssssss….. HTTP 403 error, that means we do not have permission to view this image. So we have to change the access permission for this file so that we can access it publicly. Go to the Permissions tab in the Properties of the file and click on Add more permission, Select Everyone from Grantee list and tick on the Open/Download check box and click Save.

Now try to open the file in browser again……….. and this time I can see the image.

Using the Amazon APIs we can do all the S3 tasks programmatically.
Also there is a very good Firefox plugin called S3Fox Organizer to manage the S3 accounts. It can be downloaded from http://www.s3fox.net/ . Download and install it. After installation it will come under the Tools menu of Firefox

Now run S3 Organizer. At the first run it will show the alert message to add account information and key.

Click on Manage Accounts button of S3Fox. It will ask for the Account Name and the keys. The keys are created at the time of setup of the AWS access account.

This information is available in the Security Credentials link in the Account section of http://aws.amazon.com

Copy and paste the Access Key and Secret Key from Access Credentials in Security Credentials page into the S3 Account Manager window and click on Add button to add the account information. Close this window and go to S3fox Organizer. It has a very simple graphical FTP client like interface. Left hand side I can browse my local storage and in the right side I can see my S3 account root location with my Buckets. We can see the mkcl-itinfra-diagram bucket that we have created using AWS Management Console. Now I will create another Bucket called mkcl-cloud-pricing.

Click on Create Bucket/Directory button

S3Fox do not provide option to select the Region for the bucket, by default it creates the bucket in US Standard region, but it has a option to place the bucket in Europe. It do not have the Singapore option in Region list (as Singapore is a new region, so I think in the new version of S3Fox all the new regions will come). Also it does not provide the option to set Logging for the bucket.

After creating the Bucket we can set the access control to that bucket by right clicking the bucket and clicking Edit ALC

Change the ALC as per requirement.

Also it has a cool feature to sync a local folder with a Amazon S3 folder. Click on the Synchronize Folders->Add/Remove Folders

Enter the folders to share and save it with a name.
After adding the folders we can sync the folders. Click on Synchronize Folders and on the name of the account that we want to sync (in our case the account Cloud_Pricing we created in the previous step).

It will give us alert message whether we want to upload all the files or only the files that were changed since last upload. If we click OK it will upload only the changed/new files and if we click Cancel, it will upload all the files.

I will click OK and the uploading will start.

Amazon S3 is a very good storage over internet. It can reduce online backup cost; also it is very reliable, flexible and fast. We can write our own applications or we can use the available tools to access S3.
জয় আই অসম,
প্রণব শর্মা
No comments:
Post a Comment