In my last document on replication “Replication in MySQL-Part 1”, I described the simplest of all the replication, which is replication between two new installations. Please read that document for reference.
In this document I will describe replication on an existing server. That is I have a server which is running and has data and I want to configure a new slave for the server. The new slave will be a clone of the existing server. The replication setup is as follows:

In this example I am going to use MySQL 5.0 on both master and slave. Master server will be running on RHEL 5.0 (IP 172.16.0.104) and slave server will be on windows 2003 server.
Tasks to be done on the master server
Create a replication account on the master server. With this account the slave will connect to the master.

Check whether binary logging is enabled on the master

Check the server id of the server

server_id 0 menas that the server is not assigned any server id.
In my case the server does not have server_id assigned and binary logging is also not enabled. So I am going to do it now as follows:
log-bin
This option tells MySQL to start binary logging. By default the binary log files are created in MySQL’s data directory. If we want to place the binary log files into some other place we can supply path and filename (se the image below)
now the binary log files will be created in the /mysqlbinlog folder and the files will be named as mysql-bin.xxxxxx (x is 0 to 9).
server-id = 1
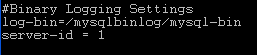
server-id must be a positive integer value from 1 to 232 – 1.
Restart the master server. Check the master server has created the index file and binary log file. If it doesn’t check the MySQL’s error file.
Now we have to make a snapshot of the master server’s data.
There are many ways to do it, depending on the choice, storage engine and downtime available. I am mentioning three options (A, B and C)here:
A) Using archiving program to make binary backup of the databases:
Before starting the backup, flush all the tables and block any changes to the database using a global read lock.

Do not close the client, from which we executed the FLASH TABLES statement till our backup is completed, otherwise it will release the read lock.
Use an archiving program to make binary backup of the databases in master’s data directory.
Also note the current binary log name and offset while the lock is on as follows:
Also note the current binary log name and offset while the lock is on as follows:

Note the value of File and Position column.
After backup is completed and binary log name and offset recorded, we can release the locks.

This backup option is mainly useful for databases with MyISAM tables.
If we are using InnoDB tables, the quickest way to take backup is to shutdown the master server and copy the InnoDB files (If we do not have InnoDB Hot Backup Tool). This option can also be used with MyISAM tables. Before we shutdown the server we have to record the binary log name and offset. For that follow the steps:
Flush all the tables and block write statement.
Record the binary log name and position.
Shutdown the server without releasing the lock.Now copy the InnoDB data files, log files and table format files. If we have MyISAM tables, copy the MyISAM tables also.
After copying is done, start the MySQL server.
C) Creating SQL dump:
This option I commonly use to take backup of the master for setting up replication. This option is useful as it can be used with both MyISAM and InnoDB tables, also we do not have to shutdown the server, but we have to apply read lock while creating the dump file, which means that select queries can run on my server, but data writes will have to wait till locks are released.
This option I commonly use to take backup of the master for setting up replication. This option is useful as it can be used with both MyISAM and InnoDB tables, also we do not have to shutdown the server, but we have to apply read lock while creating the dump file, which means that select queries can run on my server, but data writes will have to wait till locks are released.
I will show three options (i, ii and iii) of creating the dump, any of them can be used to create the SQL dump.
i) Flush tables and block write statement
i) Flush tables and block write statement
Open another console and start the dump process

Record the binary log file and position from another client
After dump is taken and log file name, position are recorded, release the lock.
ii) We can flush and lock the tables with the mysqldump program, instead of flushing and locking from a different MySQL client.

While the mysqldump program is running record the binary log file name and position (before mysqldump finishes creating the dump, otherwise it will release the lock and we will not have proper filename and position to start the replication).
Note the File and Position column.
iii) Instead of recording the binary log file name and position manually, we can tell mysqldump program to record it in the dump file that it creates. In that case we do not have to run the show master status manually.
iii) Instead of recording the binary log file name and position manually, we can tell mysqldump program to record it in the dump file that it creates. In that case we do not have to run the show master status manually.

The –master-data option writes the binary log filename and position to the output. If the –master-data value is equal to 1, the position and filename are written to the dump output in the form of a CHANGE MASTER statement. If the option value is 2 the CHANGE MASTER statement is written as comment.
Now we are done with the master server side.
Tasks to be done on the slave server
1) Assign server-id to the slave server. Open the MySQL configuration file and add the following line in [mysqld] section server-id=2
server-id must be a positive integer value from 1 to 232 – 1. It is necessary that the slave’s server-id must be different from the master’s server-id. Restart MySQL server after adding server-id.
server-id must be a positive integer value from 1 to 232 – 1. It is necessary that the slave’s server-id must be different from the master’s server-id. Restart MySQL server after adding server-id.
2) Restore the backup of the master server.
If binary backup of the master was taken, copy it to slave server’s data directory before starting the slave server. After data copy is done, start the server.
If the backup of the master was done by mysqldump, we have to load the dump file into the slave server.
If binary backup of the master was taken, copy it to slave server’s data directory before starting the slave server. After data copy is done, start the server.
If the backup of the master was done by mysqldump, we have to load the dump file into the slave server.

3) Execute the following statement on the slave server

Replace the host with your master server’s host name/IP, also the user and password.
MASTER_LOG_FILE is the binary log filename and MASTER_LOG_POS is the offset we recorded in the master while taking the snapshot of the master. If we have SQL dump file created with --master-data=2 option then we can use any tool to read the MASTER_LOG_FILE and MASTER_LOG_POS from the dump file. I used head command to read the values.
MASTER_LOG_FILE is the binary log filename and MASTER_LOG_POS is the offset we recorded in the master while taking the snapshot of the master. If we have SQL dump file created with --master-data=2 option then we can use any tool to read the MASTER_LOG_FILE and MASTER_LOG_POS from the dump file. I used head command to read the values.

4) Now the slave setup is done and we have to start the slave threads:

These are the steps we need to perform on the slave.
After we have performed the above described procedure, our slave should connect to the master and start getting the updates that have occurred in the master server since we took the snapshot.
This way we can create many slave servers for the master just by changing the server-id of the slave and repeating the above tasks for slave server. If we have the snapshot of the master and all the binary log files, we can create many slaves using that snapshot. No need to take snapshot of the master for each slave we configure.
জয় আই অসম,
প্রণব শর্মা
No comments:
Post a Comment